
The AI Mirror Effect: Why Your AI Evaluations Need Domain Experts
Everyone thought AI would be the great equalizer.
Turns out, it's the great amplifier.
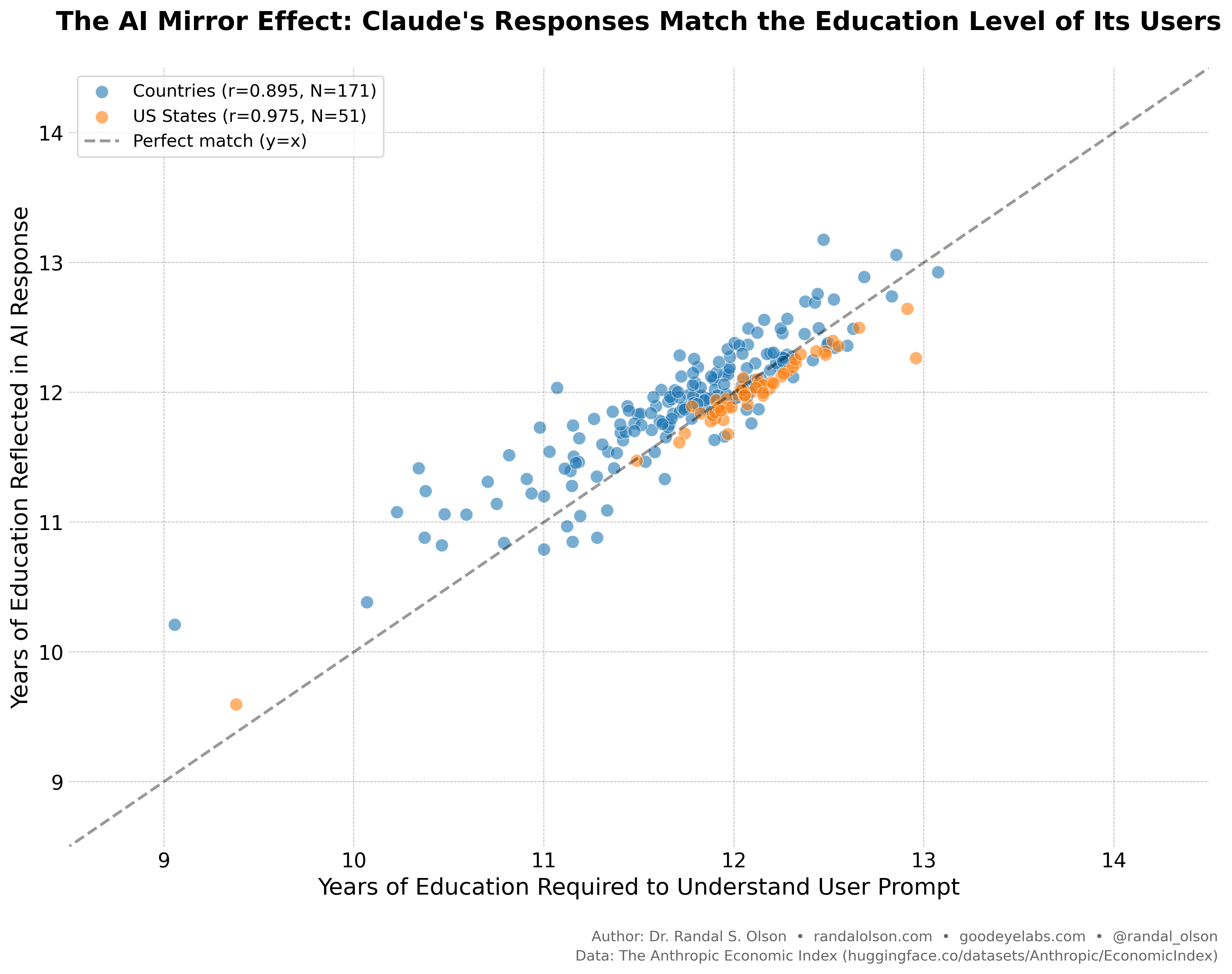
Anthropic's latest Economic Index reported a nearly perfect correlation between how sophisticated your prompt is and how sophisticated Claude's response is. They buried this finding in text. We visualized it across 222 geographies:
Understanding the Axes
Click to expand and learn how these metrics are measured
Understanding the Axes
Click to expand and learn how these metrics are measured
Anthropic measures "sophistication" using a metric they call Education Years. This is determined by asking an AI classifier to estimate the years of formal education required to understand a piece of text:
- Human education (years) (X-axis): The estimated education level required to understand the user's prompt.
- AI education (years) (Y-axis): The estimated education level required to understand the AI's response to that specific prompt.
By analyzing 1 million anonymized transcripts, Anthropic found that these two metrics are almost perfectly correlated. This high correlation shows that the sophistication of an AI's response is directly limited by the sophistication of the prompt it receives.
The pattern is clear. Sophisticated users get sophisticated outputs. Basic users get basic outputs.
In other words: AI doesn't just elevate your expertise. It mirrors it.
Here's why this matters for AI evaluation
If AI output quality perfectly tracks input sophistication (r=0.98 for US states), then your evaluation quality must track domain sophistication.
Most companies evaluate AI with generic LLM-as-a-judge systems or metrics like toxicity and helpfulness. These work fine for catching obvious failures like major factual inaccuracies, formatting errors, and tone issues. But they can't assess domain-specific quality because they lack domain grounding.
A generic AI judge can't evaluate a medical diagnosis like a doctor can. It can't grade educational content like a teacher can. It can't assess a legal brief like an attorney can.
And if your AI is serving sophisticated users, generic evaluation will systematically miss the quality issues that matter most.
In January 2026, the chief constable of West Midlands Police resigned after his department relied on Microsoft Copilot to generate an intelligence report. The AI hallucinated a football match between Maccabi Tel Aviv and West Ham that never existed. Based on this fabricated evidence, police banned Israeli fans from attending a match, sparking a national scandal and parliamentary inquiry.
A sports journalist would have caught the error instantly. Generic AI evaluations missed it.
This is the evaluation gap that's keeping AI products in beta. Companies know their AI needs to be better, but they're using evaluation systems that aren't sophisticated enough to tell them how to make it better.
Closing the evaluation gap
At Goodeye Labs, this is what we think about every day: how do you capture what a domain expert knows, translate that into evaluation criteria that scale, and deploy it so your AI team can actually measure what matters for your product?
It's harder than it sounds. Expert knowledge is often tacit. What makes a "good" medical response or a "clear" educational explanation isn't always codified. The work isn't just building an evaluation platform. It's building the methodology to systematically extract domain expertise and turn it into repeatable, scalable quality control.
That's what we're building at Goodeye. Not generic AI judging generic AI. Expert-grounded workflows that catch the quality issues your users actually care about.
Because if your AI is only as good as what you put into it, then your evaluation is only as good as who's teaching it.