
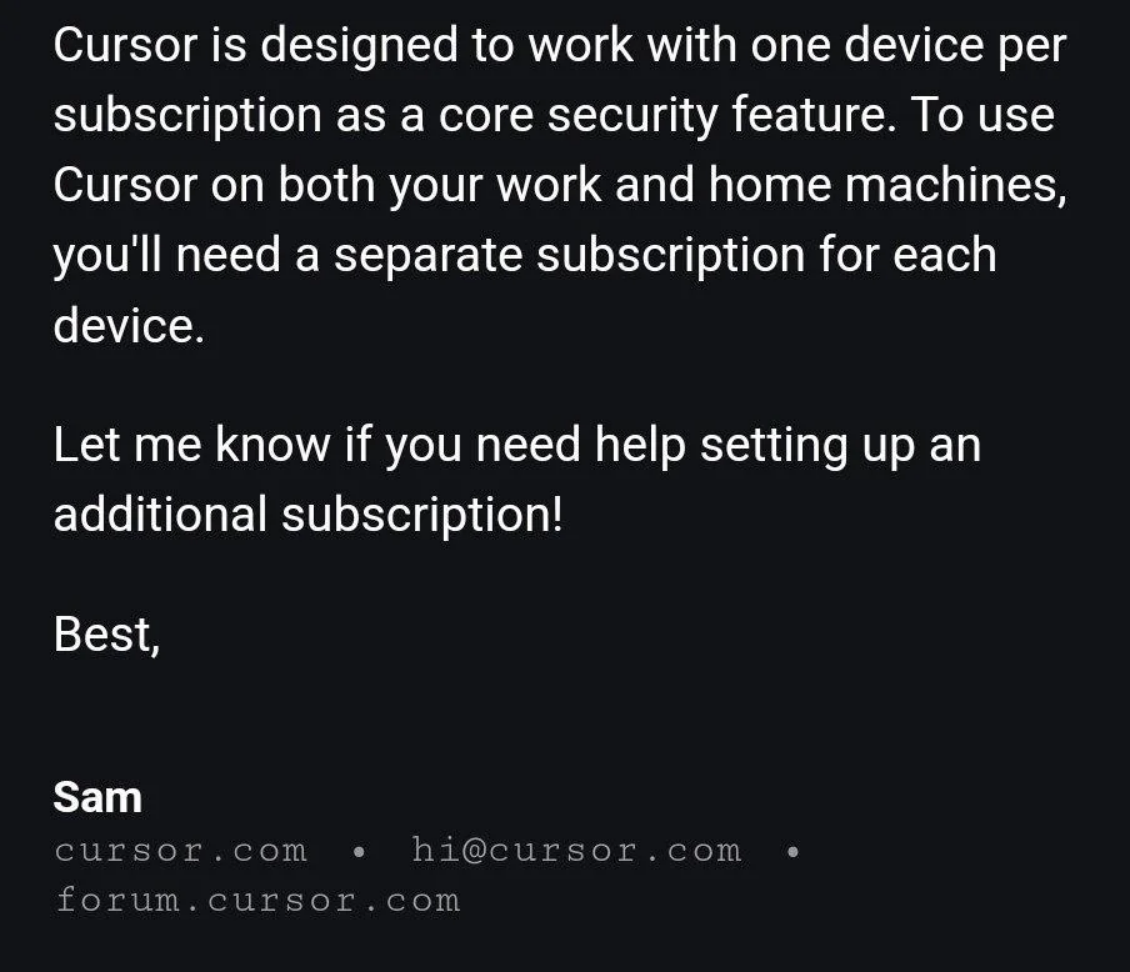
"Sam" was not a real person. It was Cursor's AI support bot.
It told multiple users about this policy.
The policy didn't exist. The AI hallucinated it.
Randy Olson, PhD
Co-Founder & CTO, Goodeye Labs
Portland AI Engineers
January 14, 2026
Why Traditional Approaches Fail
Coming Up
"Sam" was not a real person. It was Cursor's AI support bot.
It told multiple users about this policy.
The policy didn't exist. The AI hallucinated it.
Non-deterministic failures
Some users got the hallucination, others didn't
Users argued with each other
"That's not true, I switch devices all the time"
CEO had to intervene
Public apology and damage control
The haunting question
How many users got wrong answers and never said anything?
User complains
You investigate
You fix that case
Did you create a new problem?
Without systematic evaluation, you're flying blind.
# Deterministic
assert add(2, 2) == 4 # Always passes
assert add(2, 2) == 4 # Always passes
assert add(2, 2) == 4 # Always passes# Stochastic
llm("Write about AI")
# "AI is transforming..."
llm("Write about AI")
# "Artificial intelligence..."
llm("Write about AI")
# "The field of AI..."Unit tests don't work when the output is different every time
The challenge:
Building AI products, shipping to production
Sharing insights with the community
No time to write every post manually
AI must sound like me, not generic LLM
I use em dashes occasionally—but only in paired parenthetical constructions—where I'm adding a side thought.
This is amazing—truly revolutionary. The future is here—and it's incredible—beyond anything we imagined.
em_dash_count = text.count("—")
assert em_dash_count <= 5, "Too many em dashes!"Counting doesn't capture the pattern.
You can't write a regex to distinguish "dramatic" from "parenthetical."
Write in a professional tone
Write in a professional tone.
Be concise.
Don't overuse em dashes.
Write in a professional tone.
DO: [15 rules]
DON'T: [20 rules]
EXCEPTIONS: [...]
LLMs follow these lists... inconsistently
Long rule lists become noise. Edge cases multiply. You're playing whack-a-mole, not engineering.
Prompt engineering hits a wall. How do you even know if version 7 is better than version 2?
LLMs are capable of practically infinite possibility
That's their strength. It's also their weakness.
Hard-coded rules and tests
Hard-coded limits the AI must stay within
Necessary
Contextual evaluations
Match your preferences, capture nuance
Often missing
Static guardrails alone aren't enough. You need quality signals too.
LLM-as-a-Judge
Coming Up
Benchmark Evaluation
Generic tests like MMLU, HumanEval that measure general model capabilities
Measures breadth
Contextual Evaluation
Does your AI work for YOUR specific use case on YOUR specific data?
Measures depth
We're not comparing models. We're asking: does this AI output meet YOUR bar?
AI Output
LLM Judge
Pass/Fail
"Evaluate if this text overuses em dashes in a way that signals AI-generated writing"
| Sample | Description | Result |
|---|---|---|
| A | No em dashes | Pass |
| B | 2 em dashes, trailing emphasis | Pass (wrong!) |
| C | 8 em dashes, all parenthetical | Fail (wrong!) |
| D | 6 em dashes, mixed | Fail |
"Does this overuse em dashes?"
Generic pattern detection
without domain context
"Does this match Randy's specific em dash pattern?"
Task-specific quality assessment
tuned to my actual voice
Contextual Evals with Domain Expertise
Coming Up
PASS: Paired parenthetical
"I use em dashes—but only this way—for side thoughts."
FAIL: Dramatic/emphasis
"This is incredible—truly amazing."
AI Output
LLM Judge
Pass/Fail
"Evaluate if this text overuses em dashes in a way that signals AI-generated writing"
| Sample | Generic Result | Contextual Result |
|---|---|---|
| A (no em dashes) | Pass | Pass |
| B (2, trailing) | Pass | Fail |
| C (8, parenthetical) | Fail | Pass |
| D (6, mixed) | Fail | Fail |
Quality bars for your devs to tune AI features against
Regression detection when you change prompts or switch models
Continuous monitoring for drift before users notice
Block error modes before they reach users
AI agents can continuously check progress against evals, not just at the end
The eval is in the loop. The agent can't produce failing output.
Gap: Pedagogical scaffolding, curriculum alignment
Generic evals check "does this explain the concept?"
Contextual eval checks "does this address this student's gaps?"
Gap: Patient-specific risk factors, protocol compliance
Generic evals check "is this medically plausible?"
Contextual eval checks "is this the right diagnosis for this patient?"
Gap: Client suitability, compliance requirements
Generic evals check "is this reasonable advice?"
Contextual eval checks "does this match this client's goals and obligations?"
Generic measures breadth. Your application needs depth.
Myth: You need hundreds of test cases from day one
Reality:
Traditional tests break with stochastic systems
Generic LLM-as-Judge handles variability but misses domain nuance
Domain expertise closes the gap between what's measured and what matters
Integrate evals throughout dev, deploy, production, and guardrails
Start small with 20-50 examples drawn from real failures
Pick one failure mode you've already seen
Write 10 test cases for it
Define pass/fail criteria with an LLM judge
Add 10-20 labeled examples from your domain
Run it regularly in your workflow
What I demoed today
goodeyelabs.com
Comprehensive guide covering basics to advanced topics
hamel.dev/blog/posts/evals-faq
Excellent practical advice, battle-tested
anthropic.com/engineering/demystifying-evals-for-ai-agents
Open source LLM observability & evaluation
github.com/Arize-ai/phoenix
LangChain's tracing & evaluation platform
langchain.com/langsmith
Scan to get updates on Truesight
Let's connect! I'd love to hear what you build.