
Evaluation Is the Load-Bearing Part of Agent Harness Design

Anthropic published a great article on their engineering blog yesterday, “Harness design for long-running application development.”
They're writing about what happens when you build agents that work autonomously for hours. Today, the model alone doesn't get you there. You need to design the system around the model, including how it evaluates its own work, how quality standards get defined, and how agents communicate with each other about what “done” means.
Anthropic and OpenAI arrived at the same insight from different angles
Anthropic's blog post mirrors OpenAI's harness engineering post from last month in a striking way. Both teams arrived at the same conclusions. The environment, feedback loops and judgment around what the model is producing determines whether agents produce good work.
OpenAI framed it as designing environments and feedback loops. Anthropic framed it as separating generators from evaluators. They arrived at the same insight from different angles.
This is data science at work, and deeply resonates with Hamel Husain's framing that harness engineering is (mostly) data science ideas applied to AI. Similarly, we wrote an article last month about how the skills of a data scientist are becoming more and more relevant in our post The Return of the Data Scientists.
Two types of evaluations show up in agent harnesses, and only one of them will matter in the long run
A useful way to think about the evaluations that show up in these harnesses is that they fall into two groups.
The first group of evaluations exist because models aren't good enough yet. Anthropic had to build sprint decomposition and context resets because Opus 4.5 lost coherence over long tasks. When they moved to Opus 4.6, those scaffolding pieces became unnecessary and they dropped them entirely. These evaluations have a natural expiration date. As models improve, the limitations they were designed to catch simply go away.
The second group of evaluations exist because models need to be steered toward what you specifically care about. Even with Opus 4.6, Anthropic's evaluator kept catching real issues around design quality, originality, and product completeness. These evaluations exist because the output needs to reflect your taste and requirements.
No matter how capable the model gets, it still needs to know what “good” looks like for your context. If it didn't, every product built on the same model would look and feel the same, and you'd have no differentiation.
The first group is less interesting. Those problems solve themselves over time. The second group is where the real work lives, and it only grows as models take on more complex tasks. Both groups follow the same data science process, but the second group is what makes evaluation a necessity that won't go away.
How we improved our data science agent at Goodeye Labs through evaluations
While building a data science agent harness internally, we noticed the agent kept producing generic, forgettable data visualizations. The charts were all technically correct. From a capability standpoint, nothing was wrong with them. However, these charts did not communicate the insights in ways we wanted. They were tasteless.
To solve this, we used our own evaluation infrastructure Truesight and encoded Edward Tufte's visualization principles as a quality standard. We pointed our agent to Truesight and told it to improve its output until it passed the Tufte test. The charts went from “technically correct” to “technically correct and tasteful.” You can read the full writeup in our Tufte Test article.
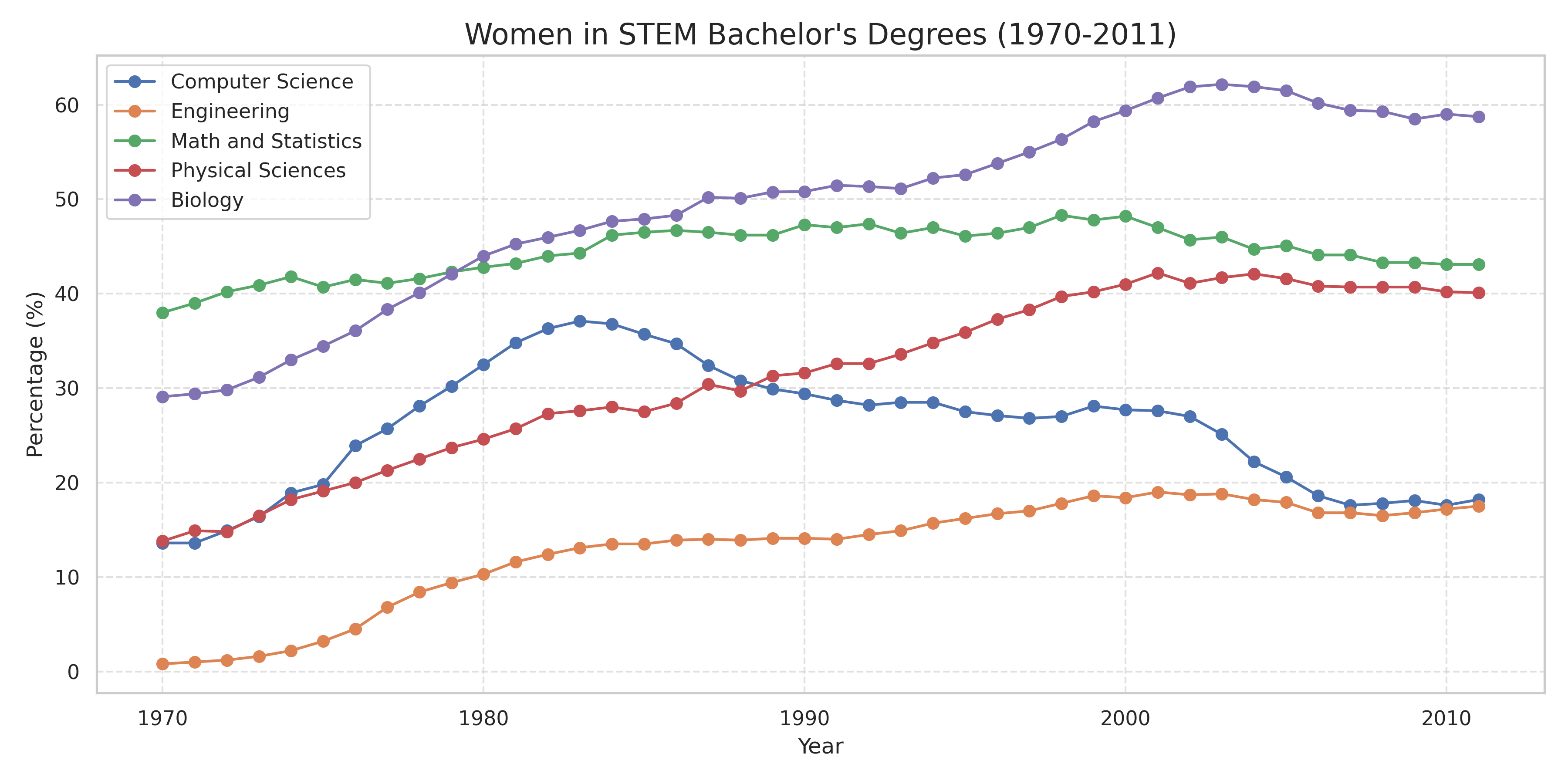
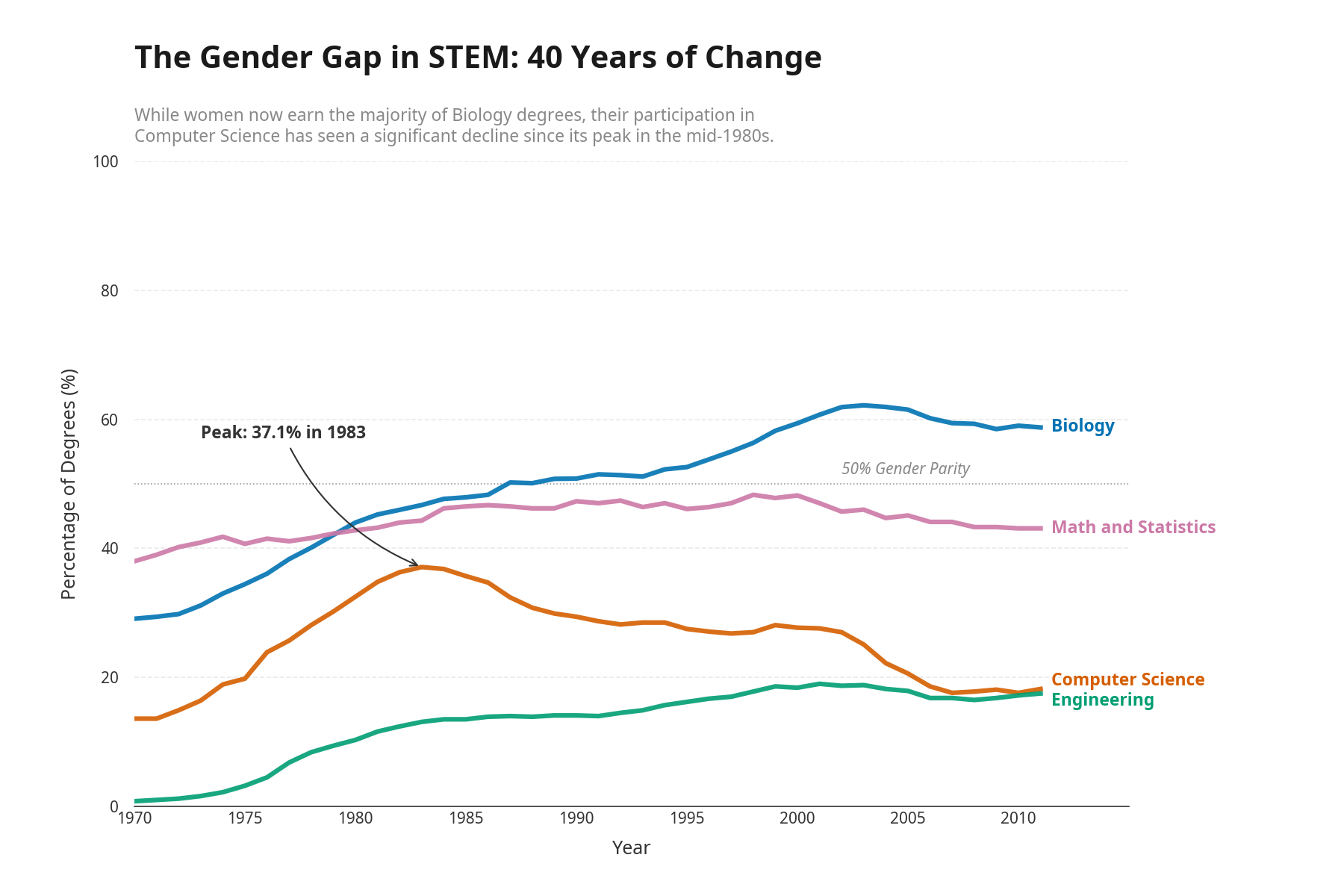
You will always need to evaluate frontier models, no matter how capable they become
As agents get more capable, being able to enforce business requirements, taste, and judgment becomes more important. Teams that can reliably measure and iterate on these subjective concepts will produce better products. Evaluations that enforce what makes your product yours will matter long after evaluations that patch model limitations become obsolete.
We'll leave you with a few quotes that resonated with us from Anthropic's blog post.
Quotes we liked
When asked to evaluate work they've produced, agents tend to respond by confidently praising the work, even when, to a human observer, the quality is obviously mediocre.
Separating the agent doing the work from the agent judging it proves to be a strong lever to address this issue.
Tuning a standalone evaluator to be skeptical turns out to be far more tractable than making a generator critical of its own work, and once that external feedback exists, the generator has something concrete to iterate against.
‘Is this design beautiful?’ is hard to answer consistently, but ‘does this follow our principles for good design?’ gives Claude something concrete to grade against.
I calibrated the evaluator using few-shot examples with detailed score breakdowns. This ensured the evaluator's judgment aligned with my preferences, and reduced score drift across iterations.
The wording of the criteria steered the generator in ways I didn't fully anticipate. Including phrases like ‘the best designs are museum quality’ pushed designs toward a particular visual convergence, suggesting that the prompting associated with the criteria directly shaped the character of the output.
Out of the box, Claude is a poor QA agent. In early runs, I watched it identify legitimate issues, then talk itself into deciding they weren't a big deal and approve the work anyway.
The tuning loop was to read the evaluator's logs, find examples where its judgment diverged from mine, and update the QA's prompt to solve for those issues. It took several rounds of this development loop before the evaluator was grading in a way that I found reasonable.
Before each sprint, the generator and evaluator negotiated a sprint contract: agreeing on what ‘done’ looked like for that chunk of work before any code was written.
Every component in a harness encodes an assumption about what the model can't do on its own, and those assumptions are worth stress testing, both because they may be incorrect, and because they can quickly go stale as models improve.
My conviction is that the space of interesting harness combinations doesn't shrink as models improve. Instead, it moves, and the interesting work for AI engineers is to keep finding the next novel combination.